
JAX London speaker Martin Gorner shows you how to: set up your Google Cloud Platform project to use Cloud Dataflow, create a Maven project with the Cloud Dataflow SDK and examples, and run an example pipeline using the Google Cloud Platform Console.
Before you begin
- Select or create a Cloud Platform Console project.
Go to the Projects page - Enable billing for your project.
Enable billing - Enable the Cloud Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, and Cloud Datastore APIs.
Enable the APIs - Install the Cloud SDK.
- Authenticate
gcloudwith Google Cloud Platform:gcloud init
- Create a Cloud Storage bucket:
- In the Cloud Platform Console, go to the Cloud Storage browser.
Go to the Cloud Storage browser - Click Create bucket.
- In the Create bucket dialog, specify the following attributes:
- Name: A unique bucket name. Do not include sensitive information in the bucket name, as the bucket namespace is global and publicly visible.
- Storage class: Standard
- Location: United States
- Click Create.
- In the Cloud Platform Console, go to the Cloud Storage browser.
- Download and install the Java Development Kit (JDK) version 1.7 or later. Verify that the JAVA_HOME environment variable is set and points to your JDK installation.
- Download and install Apache Maven by following Maven’s installation guide for your specific operating system.
Create a Maven Project that contains the Cloud Dataflow SDK for Java and Examples
-
- Create a Maven project containing the Cloud Dataflow SDK for Java using the Maven Archetype Plugin. Run the
mvn archetype:generatecommand in your shell or terminal as follows:mvn archetype:generate \ -DarchetypeArtifactId=google-cloud-dataflow-java-archetypes-examples \ -DarchetypeGroupId=com.google.cloud.dataflow \ -DgroupId=com.example \ -DartifactId=first-dataflow \ -Dversion="[1.0.0,2.0.0]" \ -DinteractiveMode=false \ -Dpackage=com.google.cloud.dataflow.examples
- Create a Maven project containing the Cloud Dataflow SDK for Java using the Maven Archetype Plugin. Run the
After running the command, you should see a new directory called first-dataflow under your current directory. first-dataflow contains a Maven project that includes the Cloud Dataflow SDK for Java and example pipelines.
Run an Example Pipeline on the Cloud Dataflow Service
- Change to the
first-dataflow/directory. - Build and run the Cloud Dataflow example pipeline called WordCount on the Cloud Dataflow managed service by using the
mvn compile exec:javacommand in your shell or terminal window. For the--projectargument, you’ll need to specify the Project ID for the Cloud Platform project that you created. For the--stagingLocationand--outputarguments, you’ll need to specify the name of the Cloud Storage bucket you created as part of the path.For example, if your Cloud Platform Project ID is my-cloud-project and your Cloud Storage bucket name is my-wordcount-storage-bucket, enter the following command to run the WordCount pipeline:mvn compile exec:java \ -Dexec.mainClass=com.google.cloud.dataflow.examples.WordCount \ -Dexec.args="--project=<my-cloud-project> \ --stagingLocation=gs://<my-wordcount-storage-bucket>/staging/ \ --output=gs://<your-bucket-id>/output \ --runner=BlockingDataflowPipelineRunner" - Check that your job succeeded:
- Open the Cloud Dataflow Monitoring UI in the Google Cloud Platform Console.
Go to the Cloud Dataflow Monitoring UI
You should see your wordcount job with a status of Running at first, and then Succeeded:
- Open the Cloud Dataflow Monitoring UI in the Google Cloud Platform Console.

- Open the Cloud Storage Browser in the Google Cloud Platform Console.Go to the Cloud Storage browser
In your bucket, you should see the output files and staging files that your job created: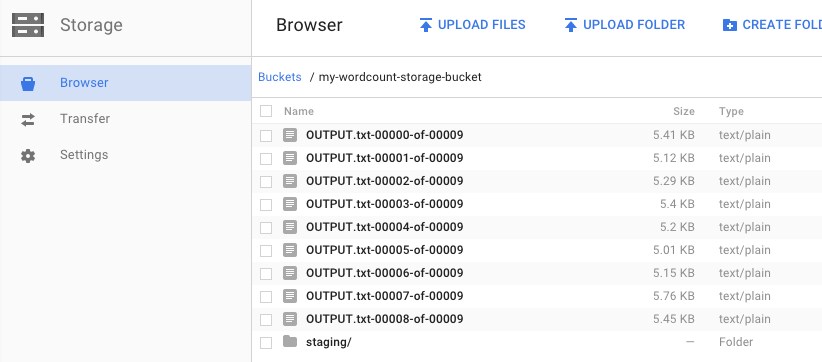
Clean up
To avoid incurring charges to your Google Cloud Platform account for the resources used in this quickstart:
- Open the Cloud Storage browser in the Google Cloud Platform Console.
- Select the checkbox next to the bucket that you created.
- Click DELETE.
- Click Delete to permanently delete the bucket and its contents.
JAX London talks by Martin Gorner:




